2. Provenance Tutorial¶
The goal of this section is to give more details on how AiiDA runs and stores data-driven workflows. At the end of it you will know how to:
Store data in the database and subsequently retrieve it.
Decorate a Python function such that its inputs and outputs are automatically tracked.
Run and monitor the status of processes.
Explore and visualize the provenance graph.
2.1. Provenance¶
Before we dive in, we need to briefly introduce one of the most important concepts for AiiDA: provenance. An AiiDA database does not only contain the results of your calculations, but also their inputs and each step that was executed to obtain them. All of this information is stored in the form of a directed acyclic graph (DAG). As an example, Fig. 2.1 shows the provenance of the calculations of this tutorial.
Fig. 2.1 Provenance Graph of a basic AiiDA WorkChain.¶
In the provenance graph, you can see different types of nodes represented by different shapes.
The green ellipses are Data nodes, the blue ellipse is a Code node, and the rectangles represent processes, i.e. the calculations performed in your workflow.
The provenance graph allows us to not only see what data we have, but also how it was produced. During this tutorial we will be using AiiDA to generate the provenance graph in Fig. 2.5 step by step.
2.2. Data nodes¶
Before running any calculations, let’s create and store a data node. AiiDA ships with an interactive IPython shell that has many basic AiiDA classes pre-loaded. To start the IPython shell, simply type in the terminal:
$ verdi shell
AiiDA implements data node types for the most common types of data (int, float, str, etc.), which you can extend with your own (composite) data node types if needed.
For this tutorial, we’ll keep it very simple, and start by initializing an Int node and assigning it to the node variable:
In [1]: node = Int(2)
We can check the contents of the node variable like this:
In [2]: node
Out[2]: <Int: uuid: de5c6cde-a420-405f-b1e5-85519b64efda (unstored) value: 2>
Quite a bit of information on our freshly created node is returned:
The data node is of the type
IntThe node has the universally unique identifier (UUID), which will be different in each case (in the example above, it turned out to be
de5c6cde-a420-405f-b1e5-85519b64efda)The node is currently not stored in the database
(unstored)The integer value of the node is
2
Let’s store the node in the database:
In [3]: node.store()
Out[3]: <Int: uuid: de5c6cde-a420-405f-b1e5-85519b64efda (pk: 146) value: 2>
As you can see, the data node has now been assigned a primary key (PK), a number that identifies the node in your database (pk: 146).
The PK and UUID both reference the node with the only difference that the PK is unique for your local database only, whereas the UUID is a globally unique identifier and can therefore be used between different databases.
Important
It is likely that the PK numbers shown throughout this tutorial are different for your database! Moreover, the UUIDs are generated randomly and are therefore guaranteed to be different.
Make a note of the PK of the Int node above, we’ll be using it later in the tutorial.
In the commands that follow, replace <PK>, or <UUID> by the appropriate identifier.
Next, let’s leave the IPython shell by typing exit() and then enter.
Back in the terminal, use the verdi command line interface (CLI) to check the data node we have just created:
$ verdi node show <PK>
Property Value
----------- ------------------------------------
type Int
pk 146
uuid de5c6cde-a420-405f-b1e5-85519b64efda
label
description
ctime 2020-11-29 14:47:04.196421+00:00
mtime 2020-11-29 14:47:13.108914+00:00
Once again, we can see that the node is of type Int, has PK = 146, and UUID = de5c6cde-a420-405f-b1e5-85519b64efda.
Besides this information, the verdi node show command also shows the (empty) label and description, as well as the time the node was created (ctime) and last modified (mtime).
See also
AiiDA already provides many standard data types, but you can also create your own.
When should I use the PK and when should I use the UUID?
A PK is a short integer identifying the node and therefore easy to remember. However, the same PK number (e.g., PK=10) might appear in two different databases referring to two completely different pieces of data.
A UUID has instead the nice feature of being globally unique: even if you export your data and a colleague imports it, the UUIDs will remain the same (while the PKs will typically be different).
Therefore, use the UUID to keep a long-term reference to a node, but feel free to use the PK for quick, everyday use in your own database.
UUID/PK - Tips and tricks
All AiiDA commands that accept a PK can also accept a UUID. Check this by trying the command before, this time with verdi node show <UUID>.
Note the following:
AiiDA does not require the full UUID, but just the first part of it, as long as only one node starts with the string you provide. E.g., in the example above, you could also say
verdi node show de5c6cde-a420. Once you start having a lot of nodes in your database,verdi node show demight return an error, since at that point you can have more than one node starting with the stringde.By default, if what you pass is a valid integer, AiiDA will assume it is a PK; if at least one of the characters is not a digit, then AiiDA will assume it is (the first part of) a UUID.
How to solve the issue, then, when the first part of the UUID is composed only by digits (e.g. in
2495301c-dd00-42d6-92e4-1a8c171bbb4a)? Indeed, usingverdi node show 24953would look for a node withPK=24953. As a solution, just add a dash, e.g.verdi node show 24953-so that AiiDA will consider this as the beginning of the UUID.Note that you can put the dash in any part of the string, and you don’t need to respect the typical UUID pattern with 8-4-4-4-12 characters per section: AiiDA will anyway first strip all dashes, and then put them back in the right place, so e.g.
verdi node show 24-95-3will give you the same result asverdi node show 24953-.
Try to use again verdi node show on the Int node above, just with the first part of the UUID (that you got from the first call to verdi node show above).
2.3. Calculation functions¶
Once your data is stored in the database, it is ready to be used for some computational task.
For example, let’s say you want to multiply two Int data nodes.
The following Python function:
def multiply(x, y):
return x * y
will give the desired result when applied to two Int nodes, but the calculation will not be stored in the provenance graph.
However, we can use a Python decorator provided by AiiDA to automatically make it part of the provenance graph.
Start up the AiiDA IPython shell again using verdi shell and execute the following code snippet:
In [1]: from aiida.engine import calcfunction
...:
...: @calcfunction
...: def multiply(x, y):
...: return x * y
This converts the multiply function into an AiIDA calculation function, the most basic execution unit in AiiDA.
Next, load the Int node you have created in the previous section using the load_node function and the PK of the data node:
In [2]: x = load_node(pk=<PK>)
Of course, we need another integer to multiply with the first one.
Let’s create a new Int data node and assign it to the variable y:
In [3]: y = Int(3)
Now it’s time to multiply the two numbers!
In [4]: multiply(x, y)
Out[4]: <Int: uuid: 752cca48-8dff-4dcb-88bd-8f5cf55e68cf (pk: 149) value: 6>
Success!
The calcfunction-decorated multiply function has multiplied the two Int data nodes and returned a new Int data node whose value is the product of the two input nodes.
Note that by executing the multiply function, all input and output nodes are automatically stored in the database:
In [5]: y
Out[5]: <Int: uuid: 075ca5b4-b9a4-4387-9e7b-0953bdf6bb13 (pk: 147) value: 3>
We had not yet stored the data node assigned to the y variable, but by providing it as an input argument to the multiply function, it was automatically stored with PK = 147.
Similarly, the returned Int node with value 6 has been stored with PK = 149.
Let’s once again leave the IPython shell with exit() and look for the process we have just run using the verdi CLI:
$ verdi process list
The returned list will be empty, but don’t worry!
By default, verdi process list only returns the active processes.
If you want to see all processes (i.e. also the processes that are terminated), simply add the -a option:
$ verdi process list -a
PK Created Process label Process State Process status
---- --------- ---------------------------- --------------- ----------------
107 5m ago PwBandsWorkChain ⏹ Finished [0]
108 5m ago seekpath_structure_analysis ⏹ Finished [0]
115 5m ago PwBaseWorkChain ⏹ Finished [0]
117 5m ago create_kpoints_from_distance ⏹ Finished [0]
121 5m ago PwCalculation ⏹ Finished [0]
129 5m ago PwCalculation ⏹ Finished [0]
137 5m ago PwBaseWorkChain ⏹ Finished [0]
140 5m ago PwCalculation ⏹ Finished [0]
148 25s ago multiply ⏹ Finished [0]
Total results: 9
Info: last time an entry changed state: 24s ago (at 14:48:08 on 2020-11-29)
Notice how the band structure workflow (PwBandsWorkChain) you ran in the Quantum ESPRESSO app of AiiDAlab is also in the process list!
Moreover, we can see that our multiply calculation function was created 1 minute ago, assigned the PK 148, and has Finished.
As a final step, let’s have a look at the provenance of this simple calculation.
The provenance graph can be automatically generated using the verdi CLI.
Let’s generate the provenance graph for the multiply calculation function we have just run:
$ verdi node graph generate <PK>
The command will write the provenance graph to a .pdf file.
If you open a file manager on the start page, you should be able to see and open the PDF.
It should look something like the graph shown in Fig. 2.2.
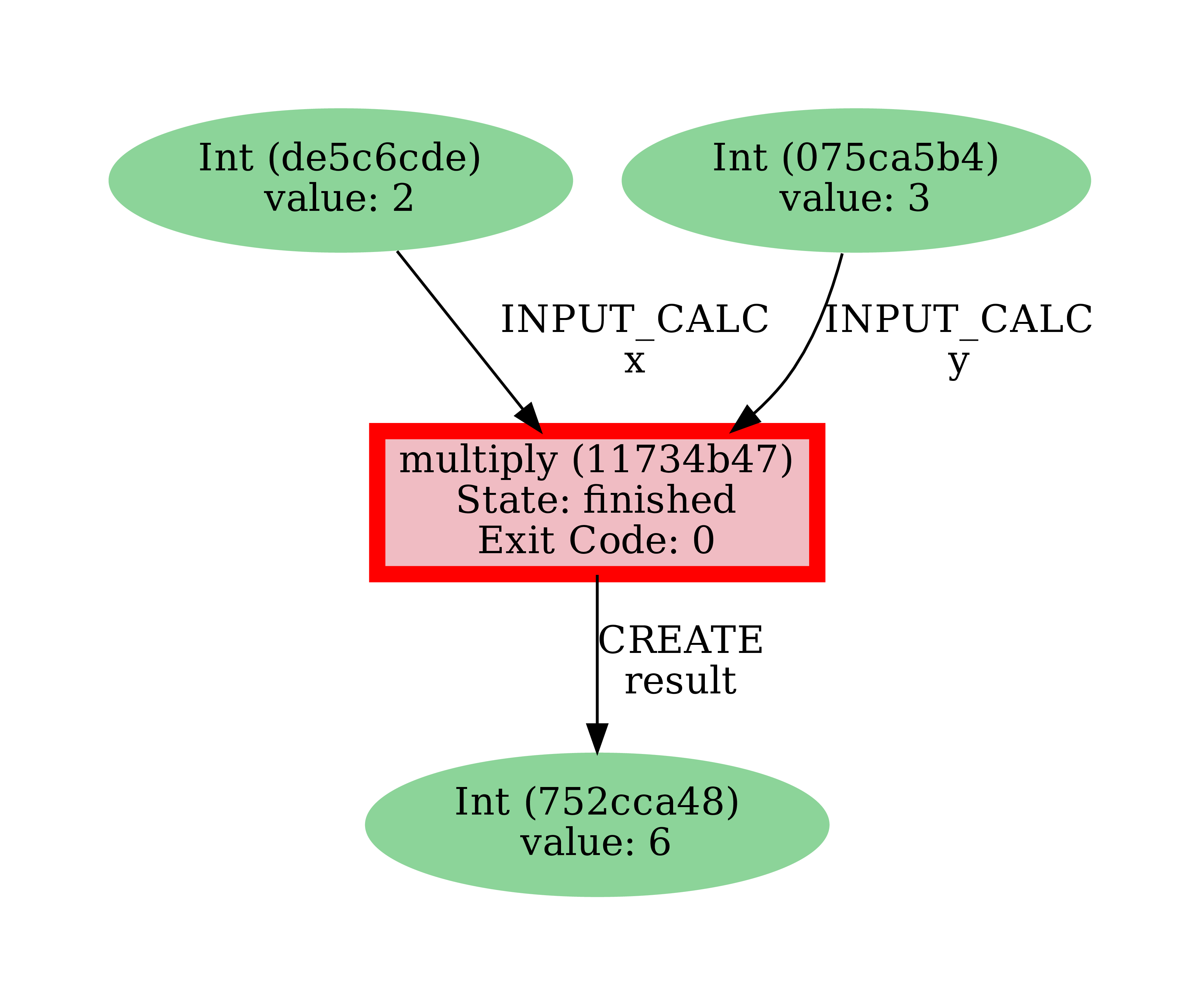
Fig. 2.2 Provenance graph of the multiply calculation function.¶
Note
Remember that the PK of the calcfunction can be different for your database, and that the UUID will always be different.
2.4. CalcJobs¶
When running calculations that require an external code or run on a remote machine, a simple calculation function is no longer sufficient.
For this purpose, AiiDA provides the CalcJob process class.
To run a CalcJob, you need to set up two things: a code that is going to implement the desired calculation and a computer for the calculation to run on.
AiiDAlab ships with the localhost computer set up, which is the one we’ll be using throughout the tutorial.
However, we still have to set up the add code, which we’ll be using for this section:
$ verdi code setup --label add --computer localhost --input-plugin arithmetic.add --remote-abs-path /bin/bash --non-interactive
Success: Code<150> add@localhost created
This command sets up a code with label add on the computer localhost, using the plugin arithmetic.add.
The absolute path to the “remote” executable is \bin\bash, i.e. this code simply prepares and runs a bash script.
Finally, the non-interactive option (-n) is added to not prompt for extra input.
Note
As you can see, the Code node has also been assigned a PK in the database (150), and hence can be a part of the provenance.
A typical real-world example of a computer is a remote supercomputing facility. Codes can be anything from a Python script to powerful ab initio codes such as Quantum ESPRESSO or machine learning tools like TensorFlow.
See also
More details on how to run external codes.
Let’s have a look at the codes that are available to us:
$ verdi code list
# List of configured codes:
# (use 'verdi code show CODEID' to see the details)
* pk 1 - pw@localhost
* pk 150 - add@localhost
The first code is the one you set up in the AiiDAlab Quantum ESPRESSO app earlier.
The second one in the list is the code you have just set up: add@localhost with PK = 150.
This code allows us to add two integers together.
The add@localhost identifier indicates that the code with label add is run on the computer with label localhost.
To see more details about the computer, you can use the following verdi command:
$ verdi computer show localhost
-------------- ------------------------------------
Label localhost
PK 1
UUID 43cc04f9-92f0-4a5c-9019-2bf679c1dece
Description this computer
Hostname localhost
Transport type local
Scheduler type direct
Work directory /home/aiida/aiida_run/
Shebang #!/bin/bash
Mpirun command mpirun -np {tot_num_mpiprocs}
Prepend text
Append text
-------------- ------------------------------------
The localhost computer has PK = 1, UUID 43cc04f9-92f0-4a5c-9019-2bf679c1dece, and has the following setup:
Set up on the
localhost.Uses the
localtransport.Uses a direct scheduler.
The work directory, where the calculations will run, is set up in
/home/aiida/aiida_run/.The launch script uses the
#!/bin/bashshebang interpreter directive.The mpirun command is
mpirun -np {tot_num_mpiprocs}. Note that{tot_num_mpiprocs}will be replaced during the preparation of the calculation for submission.
Note
You may have noticed that the PK of the localhost computer is the same as the pw@localhost code, which is represented by a node in the database.
This is because different entities, such as nodes, computers and groups, are stored in different tables of the database.
So, the PKs for each entity type are unique for each database, but entities of different types can have the same PK within one database.
Let’s now start up the verdi shell again and load the add@localhost code using its label:
In [1]: code = load_code(label='add')
Every code has a convenient tool for setting up the required input, called the builder.
It can be obtained by using the get_builder method:
In [2]: builder = code.get_builder()
Using the builder, you can easily set up the calculation by directly providing the input arguments.
Let’s use the Int node that was created by our previous calcfunction as one of the inputs and a new node as the second input:
In [3]: builder.x = load_node(pk=<PK>)
...: builder.y = Int(5)
In case you don’t remember the PK of the output node from the previous calculation, check the provenance graph you generated earlier and use the UUID of the output node instead:
In [3]: builder.x = load_node(uuid='<UUID>')
...: builder.y = Int(5)
Note how you don’t have to provide the entire UUID to load the node. As long as the first part of the UUID is unique within your database, AiiDA will find the node you are looking for.
Note
One nifty feature of the builder is the ability to use tab completion for the inputs.
Try it out by typing builder. + <TAB> in the verdi shell.
To execute the CalcJob, we use the run function provided by the AiiDA engine:
In [4]: from aiida.engine import run
...: run(builder)
Wait for the process to complete. Once it is done, it will return a dictionary with the output nodes:
Out[4]:
{'sum': <Int: uuid: 9487718e-fbb7-45c6-815a-a2a6db4d3d5d (pk: 155) value: 11>,
'remote_folder': <RemoteData: uuid: 4b6fc278-4784-4b05-8cc0-2b865e36578d (pk: 153)>,
'retrieved': <FolderData: uuid: 95d6fb83-b3c4-4252-ba9a-fa259be48cf1 (pk: 154)>}
Besides the sum of the two Int nodes, the calculation function also returns two other outputs: one of type RemoteData and one of type FolderData.
See the topics section on calculation jobs for more details.
Now, exit the IPython shell and once more check for all processes:
$ verdi process list --all
PK Created Process label Process State Process status
---- --------- ---------------------------- --------------- ----------------
<! OUTPUT REMOVED !>
148 14m ago multiply ⏹ Finished [0]
152 19s ago ArithmeticAddCalculation ⏹ Finished [0]
Total results: 10
Info: last time an entry changed state: 16s ago (at 15:02:51 on 2020-11-29)
Note that we’ve removed the output regarding the band structure calculation that you ran in the AiiDAlab Quantum ESPRESSO app earlier.
We now see two arithmetic processes in the list.
One is the multiply calcfunction you ran earlier, the second is the ArithmeticAddCalculation calculation job that you have just run.
Grab the PK of the ArithmeticAddCalculation, and generate the provenance graph.
The result should look like the graph shown in Fig. 2.3.
$ verdi node graph generate <PK>
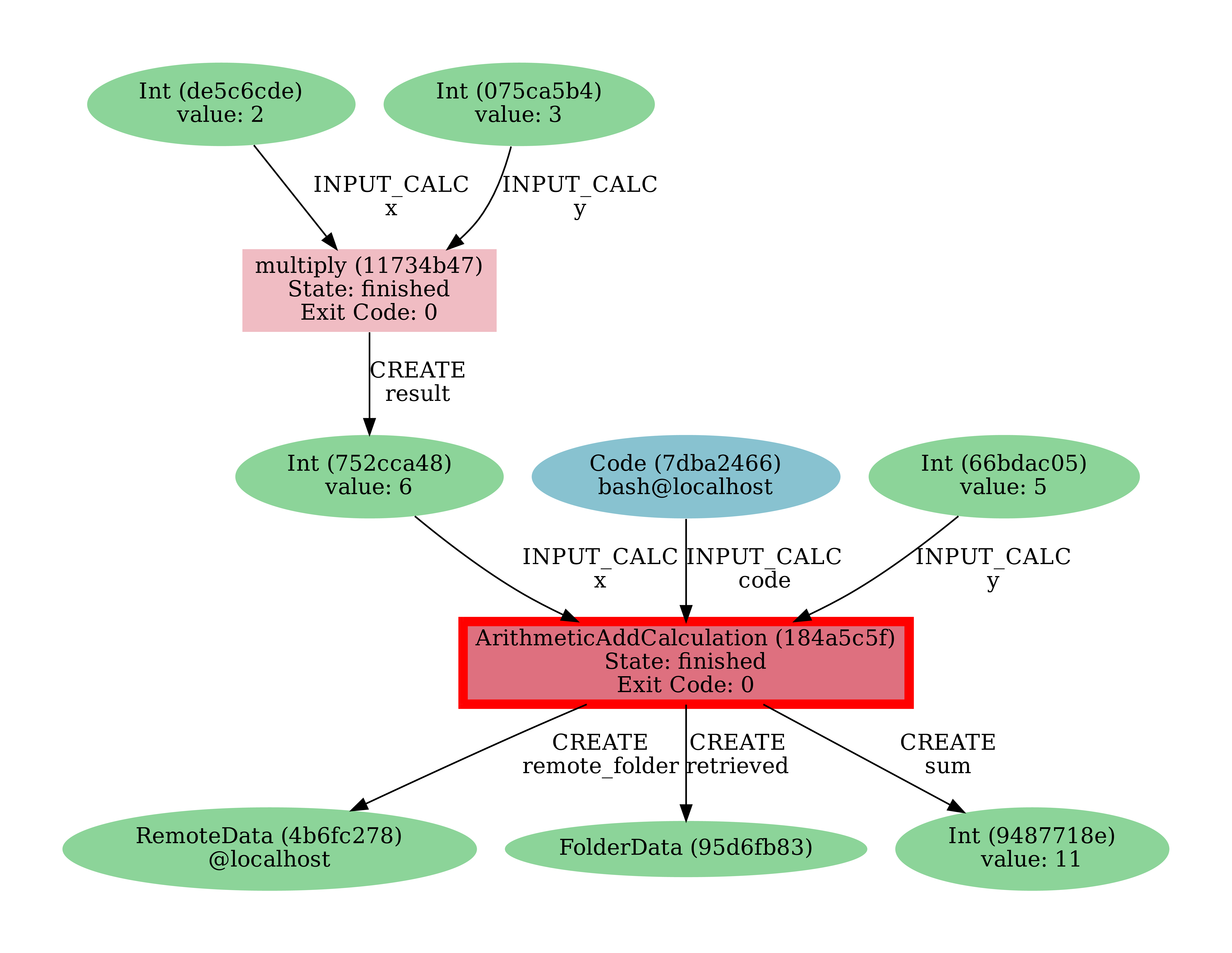
Fig. 2.3 Provenance graph of the ArithmeticAddCalculation CalcJob, with one input provided by the output of the multiply calculation function.¶
You can see more details on any process, including its inputs and outputs, using the verdi shell:
$ verdi process show <PK>
Property Value
----------- ------------------------------------
type ArithmeticAddCalculation
state Finished [0]
pk 152
uuid 184a5c5f-0ea3-4bf6-957b-75490b6013e4
label
description
ctime 2020-11-29 15:02:48.595695+00:00
mtime 2020-11-29 15:02:51.647130+00:00
computer [1] localhost
Inputs PK Type
-------- ---- ------
code 150 Code
x 149 Int
y 151 Int
Outputs PK Type
------------- ---- ----------
remote_folder 153 RemoteData
retrieved 154 FolderData
sum 155 Int
2.5. Submitting to the daemon¶
When we used the run command in the previous section, the IPython shell was blocked while it was waiting for the CalcJob to finish.
This is not a problem when we’re simply adding two numbers together, but if we want to run multiple calculations that take hours or days, this is no longer practical.
Instead, we are going to submit the CalcJob to the AiiDA daemon.
The daemon is a program that runs in the background and manages submitted calculations until they are terminated.
Let’s first check the status of the daemon using the verdi CLI:
$ verdi daemon status
If the daemon is running, the output will be something like the following:
Profile: default
Daemon is running as PID 1033 since 2020-11-29 14:37:59
Active workers [1]:
PID MEM % CPU % started
----- ------- ------- -------------------
1036 0.415 0 2020-11-29 14:38:00
In this case, let’s stop it for now:
$ verdi daemon stop
Profile: default
Waiting for the daemon to shut down... OK
Next, let’s submit the CalcJob we ran previously.
Start the verdi shell and execute the Python code snippet below.
This follows all the steps we did previously, but now uses the submit function instead of run:
In [1]: from aiida.engine import submit
...:
...: code = load_code(label='add')
...: builder = code.get_builder()
...: builder.x = load_node(pk=<PK>)
...: builder.y = Int(5)
...:
...: submit(builder)
When using submit the calculation job is not run in the local interpreter but is sent off to the daemon and you get back control instantly.
Instead of the result of the calculation, it returns the node of the CalcJob that was just submitted:
Out[1]: <CalcJobNode: uuid: 5f0025b3-8d44-46fb-b627-9d8be71c0e86 (pk: 157) (aiida.calculations:arithmetic.add)>
Let’s exit the IPython shell and have a look at the process list:
$ verdi process list
PK Created Process label Process State Process status
---- --------- ------------------------ --------------- ----------------
157 15s ago ArithmeticAddCalculation ⏹ Created
Total results: 1
Info: last time an entry changed state: 15s ago (at 15:04:57 on 2020-11-29)
Warning: the daemon is not running
You can see the CalcJob you have just submitted, with the state Created.
The CalcJob process is now waiting to be picked up by a daemon runner, but the daemon is currently disabled.
Let’s start it up (again):
$ verdi daemon start
Starting the daemon... RUNNING
Now you can use verdi process list to follow the progress of the calculation.
Let’s wait for the CalcJob to complete and then use verdi process list --all to see all processes we have run so far:
$ verdi process list --all
PK Created Process label Process State Process status
---- --------- ---------------------------- --------------- ----------------
<! OUTPUT REMOVED !>
148 17m ago multiply ⏹ Finished [0]
152 2m ago ArithmeticAddCalculation ⏹ Finished [0]
157 41s ago ArithmeticAddCalculation ⏹ Finished [0]
Total results: 11
Info: last time an entry changed state: 7s ago (at 15:05:31 on 2020-11-29)
2.6. Workflows¶
So far we have executed each process manually.
AiiDA allows us to automate these steps by linking them together in a workflow, whose provenance is stored to ensure reproducibility.
For this tutorial we have prepared a basic WorkChain that is already implemented in aiida-core.
You can see the code below:
MultiplyAddWorkChain code
"""Implementation of the MultiplyAddWorkChain for testing and demonstration purposes."""
from aiida.orm import Code, Int
from aiida.engine import calcfunction, WorkChain, ToContext
from aiida.plugins.factories import CalculationFactory
ArithmeticAddCalculation = CalculationFactory('arithmetic.add')
@calcfunction
def multiply(x, y):
return x * y
class MultiplyAddWorkChain(WorkChain):
"""WorkChain to multiply two numbers and add a third, for testing and demonstration purposes."""
@classmethod
def define(cls, spec):
"""Specify inputs and outputs."""
super().define(spec)
spec.input('x', valid_type=Int)
spec.input('y', valid_type=Int)
spec.input('z', valid_type=Int)
spec.input('code', valid_type=Code)
spec.outline(
cls.multiply,
cls.add,
cls.validate_result,
cls.result,
)
spec.output('result', valid_type=Int)
spec.exit_code(400, 'ERROR_NEGATIVE_NUMBER', message='The result is a negative number.')
def multiply(self):
"""Multiply two integers."""
self.ctx.product = multiply(self.inputs.x, self.inputs.y)
def add(self):
"""Add two numbers using the `ArithmeticAddCalculation` calculation job plugin."""
inputs = {'x': self.ctx.product, 'y': self.inputs.z, 'code': self.inputs.code}
future = self.submit(ArithmeticAddCalculation, **inputs)
return ToContext(addition=future)
def validate_result(self):
"""Make sure the result is not negative."""
result = self.ctx.addition.outputs.sum
if result.value < 0:
return self.exit_codes.ERROR_NEGATIVE_NUMBER
def result(self):
"""Add the result to the outputs."""
self.out('result', self.ctx.addition.outputs.sum)
First, we recognize the multiply function we have used earlier, decorated as a calcfunction.
The define class method specifies the input and output of the WorkChain, as well as the outline, which are the steps of the workflow.
These steps are provided as methods of the MultiplyAddWorkChain class.
Note
Besides work chains, workflows can also be implemented as work functions. These are ideal for workflows that are not very computationally intensive and can be easily implemented in a Python function.
Let’s run the WorkChain above!
Start up the verdi shell and load the MultiplyAddWorkChain using the WorkflowFactory:
In [1]: MultiplyAddWorkChain = WorkflowFactory('arithmetic.multiply_add')
The WorkflowFactory is a useful and robust tool for loading workflows based on their entry point, e.g. 'arithmetic.multiply_add' in this case.
Similar to a CalcJob, the WorkChain input can be set up using a builder:
In [2]: builder = MultiplyAddWorkChain.get_builder()
...: builder.code = load_code(label='add')
...: builder.x = Int(2)
...: builder.y = Int(3)
...: builder.z = Int(5)
Once the WorkChain input has been set up, we submit it to the daemon using the submit function from the AiiDA engine. Since the workflow completes very quickly, we’ll immediately execute verdi process list --all from within the IPython shell so we can catch it in progress:
In [3]: from aiida.engine import submit
...: submit(builder)
...: !verdi process list --all
Depending on which step the workflow is running, you should get something like the following:
PK Created Process label Process State Process status
---- --------- ---------------------------- --------------- ------------------------------------
<! OUTPUT REMOVED !>
148 18m ago multiply ⏹ Finished [0]
152 3m ago ArithmeticAddCalculation ⏹ Finished [0]
157 1m ago ArithmeticAddCalculation ⏹ Finished [0]
164 4s ago MultiplyAddWorkChain ⏵ Waiting Waiting for childprocesses: 167
165 3s ago multiply ⏹ Finished [0]
167 3s ago ArithmeticAddCalculation ⏵ Waiting Waiting for transport task: retrieve
Total results: 14
Info: last time an entry changed state: 0s ago (at 15:06:16 on 2020-11-29)
We can see that the MultiplyAddWorkChain is currently waiting for its child process, the ArithmeticAddCalculation, to finish.
Check the process list again for all processes (You should know how by now!).
After about half a minute, all the processes should be in the Finished state.
The verdi process status command prints a hierarchical overview of the processes called by the work chain:
$ verdi process status <PK>
MultiplyAddWorkChain<164> Finished [0] [3:result]
├── multiply<165> Finished [0]
└── ArithmeticAddCalculation<167> Finished [0]
The bracket [3:result] indicates the current step in the outline of the MultiplyAddWorkChain (step 3, with name result).
The process status is particularly useful for debugging complex work chains, since it helps pinpoint where a problem occurred.
We can now generate the full provenance graph for the WorkChain with:
$ verdi node graph generate <PK>
Look familiar? The provenance graph should be similar to the one we showed at the start of this tutorial (Fig. 2.4).
Fig. 2.4 Final provenance Graph of the basic AiiDA tutorial.¶