Dealing with Errors
Contents
Dealing with Errors¶
In this hands-on, we’ll be looking at some more advanced concepts related to workflows.
Important
Just as in the Work chains section, we will be using the computers and codes set up in the first two hands-on sessions.
the exit codes of the work chain, specified using the
spec.exit_code()method. Exit codes are used to clearly communicate known failure modes of the work chain to the user. The first and second arguments define theexit_statusof the work chain in case of failure (400) and the string that the developer can use to reference the exit code (ERROR_NEGATIVE_NUMBER). A descriptive exit message can be provided using themessagekeyword argument. For theMultiplyAddWorkChain, we demand that the final result is not a negative number, which is checked in thevalidate_resultstep of the outline.
def validate_result(self):
"""Make sure the result is not negative."""
result = self.ctx.addition.outputs.sum
if result.value < 0:
return self.exit_codes.ERROR_NEGATIVE_NUMBER
Once the ArithmeticAddCalculation calculation job is finished, the next step in the work chain is to validate the result, i.e. verify that the result is not a negative number.
After the addition node has been extracted from the context, we take the sum node from the ArithmeticAddCalculation outputs and store it in the result variable.
In case the value of this Int node is negative, the ERROR_NEGATIVE_NUMBER exit code - defined in the define() method - is returned.
Note that once an exit code is returned during any step in the outline, the work chain will be terminated and no further steps will be executed.
Exit Codes¶
Exit codes are used to clearly communicate how a process terminated.
They consist of two parts: a positive integer, called the exit status, and a message giving more detail, also called the exit message.
If the exit status is zero, which is the default, the process is said to have terminated nominally and finished successfully.
A non-zero exit status is often used to communicate that there was some kind of a problem during the execution of the process and in that case it is said to be failed.
However, the severity of the problem can vary and a non-zero exit status can also be used to just give a warning and does not necessarily mean the process suffered a critical error.
Still, in AiiDA, a non-zero exit status technically marks a process as failed and the is_failed() property will return True.
Exit codes can be defined using the exit_code() method during the process specification in the define() method.
It takes three arguments: the exit status, an exit label for easy reference and the exit message.
Take the MultiplyAddWorkChain as an example:
@classmethod
def define(cls, spec):
"""Specify inputs and outputs."""
super().define(spec)
spec.input("x", valid_type=Int)
spec.input("y", valid_type=Int)
spec.input("z", valid_type=Int)
spec.input("code", valid_type=Code)
spec.outline(
cls.multiply,
cls.add,
cls.validate_result,
cls.result,
)
spec.output("result", valid_type=Int)
spec.exit_code(
400, "ERROR_NEGATIVE_NUMBER", message="The result is a negative number."
)
It defines the ERROR_NEGATIVE_NUMBER exit code with status 410 and message 'The result is a negative number.'.
This exit code is used in the validate_result step, where the sum produced by the ArithmeticAddCalculation is validated.
def validate_result(self):
"""Make sure the result is not negative."""
result = self.ctx.addition.outputs.sum
if result.value < 0:
return self.exit_codes.ERROR_NEGATIVE_NUMBER
If the sum is negative, which is unacceptable in this fictitious example, the work chain return the exit code that corresponds to the label ERROR_NEGATIVE_NUMBER.
Note that you can use the self.exit_codes property of the WorkChain to quickly retrieve the exit code using the corresponding label.
Returning an exit code instructs the engine to abort the work chain, and set the corresponding exit status and message on the node in the provenance graph.
In principle, you can use any positive integer when you define an exit code, however, there are some naming conventions that are generally respected by plugin developers. Note that these are not enforced and so you can decide to ignore them, however, that might complicate interoperability with other plugins. The following integer ranges are reserved or suggested:
0 - 99: Reserved for internal use by
aiida-core100 - 199: Reserved for errors parsed from scheduler output of calculation jobs
200 - 299: Suggested to be used for process input validation errors
300 - 399: Suggested for critical process errors
For any other exit codes, one can use the integers from 400 and up.
The base restart work chain¶
The problem¶
You have now seen how to write a simple workflow using work chains.
The MultiplyAddWorkChain work chain, used as an example, launches a ArithmeticAddCalculation.
In the validate_result(), the work chain gets the sum output of the calculation launched in the previous add() step.
However, there is one thing that we didn’t consider here: what if the calculation failed to produce the sum?
For such a trivial example of a calculation adding two numbers, although possible, it is very unlikely that it will fail.
Nonetheless, if it were to fail, the work chain would except because the line self.ctx.addition.outputs.sum will raise an AttributeError.
In this case, where the work chain just runs a single calculation that is not such a big deal, but for real-life work chains that run a number of calculations in sequence, having the work chain except will cause all the work up to that point to be lost.
Take as an example a workflow that computes the phonons of a crystal structure using Quantum ESPRESSO:
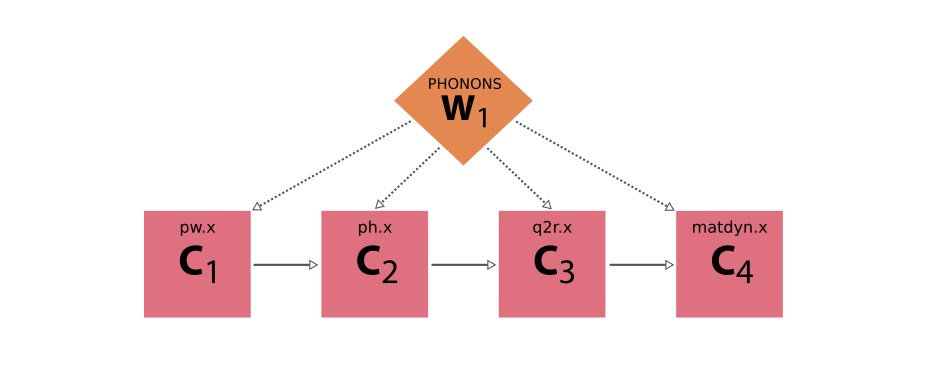
Fig. 15 Schematic diagram of a workflow that computes the phonons of a crystal structure using Quantum ESPRESSO.
The workflow consists of four consecutive calculations using the pw.x, ph.x, q2r.x and matdyn.x code, respectively.¶
If all calculations run without problems, the workflow itself will of course also run fine and produce the desired final result. But, now imagine the third calculation actually fails. If the workflow does not explicitly check for this case, but instead blindly assumes that the calculation will have produced the required results, it will fail itself, losing the progress it made with the first two calculations
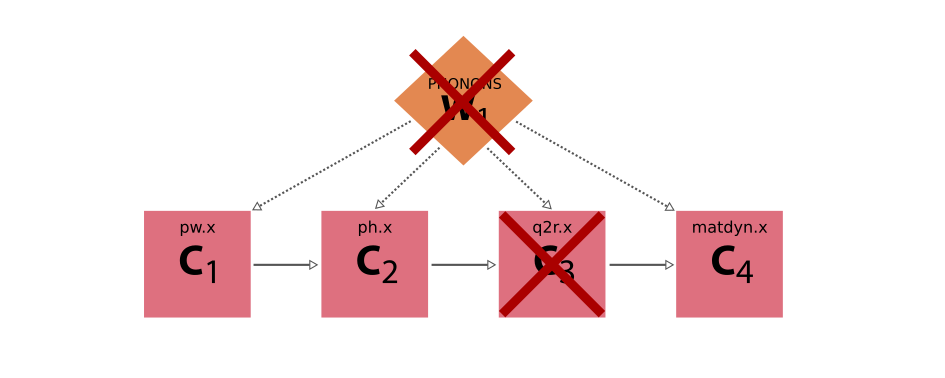
Fig. 16 Example execution of the Quantum ESPRESSO phonon workflow where the third step, the q2r.x code, failed, and because the workflow blindly assumed it would have finished without errors also fails.¶
The solution seems simple then. After each calculation, we simply add a check to verify that it finished successfully and produced the required outputs before continuing with the next calculation. What do we do, though, when the calculation failed? Depending on the cause of the failure, we might actually be able to fix the problem, and re-run the calculation, potentially with corrected inputs. A common example is that the calculation ran out of walltime (requested time from the job scheduler) and was cancelled by the job scheduler. In this case, simply restarting the calculation (if the code supports restarts), and optionally giving the job more walltime or resources, may fix the problem.
You might be tempted to add this error handling directly into the workflow.
However, you will find yourself implementing the same error-handling code many times in other workflows that just happen to have to run the same codes.
For example, we could add the error-handling for the pw.x code directly in our phonon workflow, but a structure optimization workflow will also have to run pw.x and will have to implement the same error-handling logic.
Is there a way that we can implement this once and easily reuse it in various workflows?
Yes! Instead of directly running a calculation in a workflow, one should rather run a work chain that is explicitly designed to run the calculation to completion. This base work chain knows about the various failure modes of the calculation and can try to fix the problem and restart the calculation whenever it fails, until it finishes successfully. This logic of such a base work chain is very generic and can be applied to any calculation, and actually any process:

Fig. 17 Schematic flow diagram of the logic of a base work chain, whose job it is to run a subprocess repeatedly, fixing any potential errors, until it finishes successfully.¶
The work chain runs the subprocess. Once it has finished, it then inspects the status. If the subprocess finished successfully, the work chain returns the results and its job is done. If, instead, the subprocess failed, the work chain should inspect the cause of failure, and attempt to fix the problem and restart the subprocess. This cycle is repeated until the subprocess finishes successfully. Of course this runs the risk of entering into an infinite loop if the work chain never manages to fix the problem, so we want to build in a limit to the maximum number of calculations that can be re-run:
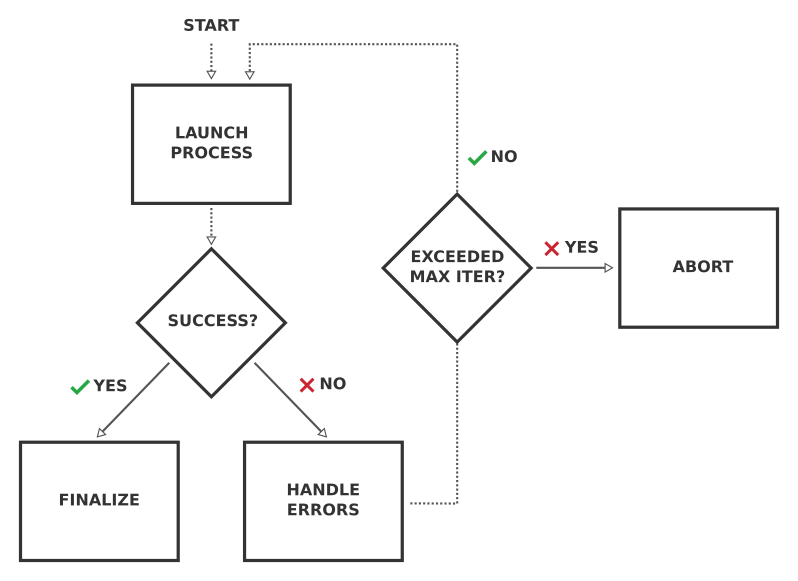
Fig. 18 An improved flow diagram for the base work chain that limits the maximum number of iterations that the work chain can try and get the calculation to finish successfully.¶
Since this is such a common logical flow for a base work chain that is to wrap another Process and restart it until it is finished successfully, we have implemented it as an abstract base class in aiida-core.
The BaseRestartWorkChain implements the logic of the flow diagram shown above.
Although the BaseRestartWorkChain is a subclass of WorkChain itself, you cannot launch it.
The reason is that it is completely general and so does not know which Process class it should run.
Instead, to make use of the base restart work chain, you should subclass it for the process class that you want to wrap.
Writing a base restart work chain¶
In this tutorial, we will show how to implement the BaseRestartWorkChain for the ArithmeticAddCalculation.
We start by importing the relevant base classes and create a subclass:
from aiida.engine import BaseRestartWorkChain
from aiida.plugins import CalculationFactory
ArithmeticAddCalculation = CalculationFactory('arithmetic.add')
class ArithmeticAddBaseWorkChain(BaseRestartWorkChain):
_process_class = ArithmeticAddCalculation
As you can see, all we had to do is create a subclass of the BaseRestartWorkChain class, which we called ArithmeticAddBaseWorkChain, and set the _process_class class attribute to ArithmeticAddCalculation.
The latter instructs the work chain what type of process it should launch.
Next, as with all work chains, we should define its process specification:
from aiida import orm
from aiida.engine import while_
@classmethod
def define(cls, spec):
"""Define the process specification."""
super().define(spec)
spec.input('x', valid_type=(orm.Int, orm.Float), help='The left operand.')
spec.input('y', valid_type=(orm.Int, orm.Float), help='The right operand.')
spec.input('code', valid_type=orm.Code, help='The code to use to perform the summation.')
spec.output('sum', valid_type=(orm.Int, orm.Float), help='The sum of the left and right operand.')
spec.outline(
cls.setup,
while_(cls.should_run_process)(
cls.run_process,
cls.inspect_process,
),
cls.results,
)
The inputs and output that we define are essentially determined by the sub process that the work chain will be running.
Since the ArithmeticAddCalculation requires the inputs x and y, and produces the sum as output, we {}mirror those in the specification of the work chain, otherwise we wouldn’t be able to pass the necessary inputs.
Finally, we define the logical outline, which if you look closely, resembles the logical flow chart presented in Fig. 18 a lot.
We start by setting up the work chain and then enter a loop: while the subprocess has not yet finished successfully and we haven’t exceeded the maximum number of iterations, we run another instance of the process and then inspect the results.
The while conditions are implemented in the should_run_process outline step.
When the process finishes successfully or we have to abandon, we report the results.
Now unlike with normal work chain implementations, we do not have to implement these outline steps ourselves.
They have already been implemented by the BaseRestartWorkChain so that we don’t have to.
This is why the base restart work chain is so useful, as it saves us from writing and repeating a lot of boilerplate code.
Warning
This minimal outline definition is required for the work chain to work properly. If you change the logic, the names of the steps or omit some steps, the work chain will not run. Adding extra outline steps to add custom functionality, however, is fine and actually encouraged if it makes sense.
The last part of the puzzle is to define in the setup what inputs the work chain should pass to the subprocess.
You might wonder why this is necessary, because we already define the inputs in the specification, but those are not the only inputs that will be passed.
The BaseRestartWorkChain also defines some inputs of its own, such as max_iterations as you can see in its define() method.
To make it absolutely clear what inputs are intended for the subprocess, we define them as a dictionary in the context under the key inputs.
One way of doing this is to reuse the setup() method:
def setup(self):
"""Call the `setup` of the `BaseRestartWorkChain` and then create the inputs dictionary in `self.ctx.inputs`.
This `self.ctx.inputs` dictionary will be used by the `BaseRestartWorkChain` to submit the process in the
internal loop.
"""
super().setup()
self.ctx.inputs = {'x': self.inputs.x, 'y': self.inputs.y, 'code': self.inputs.code}
Note that, as explained before, the setup step forms a crucial part of the logical outline of any base restart work chain.
Omitting it from the outline will break the work chain, but so will overriding it completely, except as long as we call the super.
This is all the code we have to write to have a functional work chain.
We can now launch it like any other work chain and the BaseRestartWorkChain will work its magic:
submit(ArithmeticAddBaseWorkChain, x=Int(3), y=Int(4), code=load_code('add@tutor'))
Once the work chain finished, we can inspect what has happened with, for example, verdi process status:
$ verdi process status 1909
ArithmeticAddBaseWorkChain<1909> Finished [0] [2:results]
└── ArithmeticAddCalculation<1910> Finished [0]
As you can see the work chain launched a single instance of the ArithmeticAddCalculation which finished successfully, so the job of the work chain was done as well.
Note
If the work chain excepted, make sure the directory containing the WorkChain definition is in the PYTHONPATH.
You can add the folder in which you have your Python file defining the WorkChain to the PYTHONPATH through:
$ export PYTHONPATH=/path/to/workchain/directory/:$PYTHONPATH
After this, it is very important to restart the daemon:
$ verdi daemon restart --reset
Indeed, when updating an existing work chain file or adding a new one, it is necessary to restart the daemon every time after all changes have taken place.
Exposing inputs and outputs¶
Any base restart work chain needs to expose the inputs of the subprocess it wraps, and most likely wants to do the same for the outputs it produces, although the latter is not necessary.
For the simple example presented in the previous section, simply copy-pasting the input and output port definitions of the subprocess ArithmeticAddCalculation was not too troublesome.
However, this quickly becomes tedious, and more importantly, error-prone once you start to wrap processes with quite a few more inputs.
To prevent the copy-pasting of input and output specifications, the ProcessSpec class provides the expose_inputs() and expose_outputs() methods:
@classmethod
def define(cls, spec):
"""Define the process specification."""
super().define(spec)
spec.expose_inputs(ArithmeticAddCalculation, namespace='add')
spec.expose_outputs(ArithmeticAddCalculation)
...
Calling expose_inputs() for a particular Process class, will automatically copy the inputs of the class into the inputs namespace of the process specification.
Be aware that any inputs that already exist in the namespace will be overridden.
To prevent this, the method accepts the namespace argument, which will cause the inputs to be copied into that namespace instead of the top-level namespace.
This is especially useful for exposing inputs since all processes have the metadata input.
If you expose the inputs without a namespace, the metadata input port of the exposed class will override the one of the host, which is often not what one wants.
Since there is not one output port that is shared by all process classes, it is less critical to use the namespace argument when exposing outputs.
That takes care of exposing the port specification of the wrapped process class in a very efficient way.
To efficiently retrieve the inputs that have been passed to the process, one can use the exposed_inputs() method.
Note the past tense of the method name.
The method takes a process class and an optional namespace as arguments, and will return the inputs that have been passed into that namespace when it was launched.
This utility now allows us to simplify the setup outline step that we have shown before:
def setup(self):
"""Call the `setup` of the `BaseRestartWorkChain` and then create the inputs dictionary in `self.ctx.inputs`.
This `self.ctx.inputs` dictionary will be used by the `BaseRestartWorkChain` to submit the process in the
internal loop.
"""
super().setup()
self.ctx.inputs = self.exposed_inputs(ArithmeticAddCalculation, 'add')
This way we don’t have to manually fish out all the individual inputs from the self.inputs but have to just call this single method, saving a lot of time and lines of code.
When submitting or running the work chain using namespaced inputs (add in the example above), it is important to use the namespace:
inputs = {
'add': {
'x': Int(3),
'y': Int(4),
'code': load_code('add@tutor')
}
}
submit(ArithmeticAddBaseWorkChain, **inputs)
Important
Every time you make changes to the ArithmeticAddBaseWorkChain, don’t forget to restart the daemon with:
$ verdi daemon restart --reset
Error handling¶
So far you have seen how easy it is to get a work chain up and running that will run a subprocess using the BaseRestartWorkChain.
However, the whole point of this exercise, as described in the introduction, was for the work chain to be able to deal with failing processes, yet in the previous example it finished without any problems.
What would have happened if the subprocess had failed?
If the computed sum of the inputs x and y is negative, the ArithmeticAddCalculation fails with exit code 410 which corresponds to ERROR_NEGATIVE_NUMBER.
Let’s launch the work chain with inputs that will cause the calculation to fail, e.g. by making one of the operands negative, and see what happens:
submit(ArithmeticAddBaseWorkChain, add={'x': Int(3), 'y': Int(-4), 'code': load_code('add@tutor')})
This time we will see that the work chain takes quite a different path:
$ verdi process status 1930
ArithmeticAddBaseWorkChain<1930> Finished [402] [1:while_(should_run_process)(1:inspect_process)]
├── ArithmeticAddCalculation<1931> Finished [410]
└── ArithmeticAddCalculation<1934> Finished [410]
As expected, the ArithmeticAddCalculation failed this time with a 410.
The work chain noticed the failure when inspecting the result of the subprocess in inspect_process, and in keeping with its name and design, restarted the calculation.
However, since the inputs were not changed, the calculation inevitably and wholly expectedly failed once more with the exact same error code.
Unlike after the first iteration, however, the work chain did not restart again, but gave up and returned the exit code 402 itself, which stands for ERROR_SECOND_CONSECUTIVE_UNHANDLED_FAILURE.
As the name suggests, the work chain tried to run the subprocess but it failed twice in a row without the problem being handled.
The obvious question now of course is: “How exactly can we instruct the base work chain to handle certain problems?”
Since the problems are necessarily dependent on the subprocess that the work chain will run, it cannot be implemented by the BaseRestartWorkChain class itself, but rather will have to be implemented by the subclass.
If the subprocess fails, the BaseRestartWorkChain calls a set of process handlers in the inspect_process step.
Each process handler gets passed the node of the subprocess that was just run, such that it can inspect the results and potentially fix any problems that it finds.
To “register” a process handler for a base restart work chain implementation, you simply define a method that takes a node as its single argument and decorate it with the process_handler() decorator:
from aiida.engine import process_handler, ProcessHandlerReport
class ArithmeticAddBaseWorkChain(BaseRestartWorkChain):
_process_class = ArithmeticAddCalculation
...
@process_handler
def handle_negative_sum(self, node):
"""Check if the calculation failed with `ERROR_NEGATIVE_NUMBER`.
If this is the case, simply make the inputs positive by taking the absolute value.
:param node: the node of the subprocess that was ran in the current iteration.
:return: optional :class:`~aiida.engine.processes.workchains.utils.ProcessHandlerReport` instance to signal
that a problem was detected and potentially handled.
"""
if node.exit_status == ArithmeticAddCalculation.exit_codes.ERROR_NEGATIVE_NUMBER.status:
self.ctx.inputs['x'] = orm.Int(abs(node.inputs.x.value))
self.ctx.inputs['y'] = orm.Int(abs(node.inputs.y.value))
return ProcessHandlerReport()
The method name can be anything as long as it is a valid Python method name and does not overlap with one of the base work chain’s methods.
For better readability, it is, however, recommended to have the method name start with handle_.
In this example, we want to specifically check for a particular failure mode of the ArithmeticAddCalculation, so we compare the exit_status() of the node with that of the spec of the process.
If the exit code matches, we know that the problem was due to the sum being negative.
Fixing this fictitious problem for this example is as simple as making sure that the inputs are all positive, which we can do by taking the absolute value of them.
We assign the new values to the self.ctx.inputs just as where we defined the original inputs in the setup step.
Finally, to indicate that we have handled the problem, we return an instance of ProcessHandlerReport.
This will instruct the work chain to restart the subprocess, taking the updated inputs from the context.
With this simple addition, we can now launch the work chain again:
$ verdi process status 1941
ArithmeticAddBaseWorkChain<1941> Finished [0] [2:results]
├── ArithmeticAddCalculation<1942> Finished [410]
└── ArithmeticAddCalculation<1947> Finished [0]
This time around, although the first subprocess fails again with a 410, the new process handler is called.
It “fixes” the inputs, and when the work chain restarts the subprocess with the new inputs it finishes successfully.
With this simple process you can add as many process handlers as you would like to deal with any potential problem that might occur for the specific subprocess type of the work chain implementation.
To make the code even more readable, the process_handler() decorator comes with various syntactic sugar.
Instead of having a conditional at the start of each handler to compare the exit status of the node to a particular exit code of the subprocess, you can define it through the exit_codes keyword argument of the decorator:
@process_handler(exit_codes=ArithmeticAddCalculation.exit_codes.ERROR_NEGATIVE_NUMBER)
def handle_negative_sum(self, node):
"""Handle the `ERROR_NEGATIVE_NUMBER` failure mode of the `ArithmeticAddCalculation`."""
self.ctx.inputs['x'] = orm.Int(abs(node.inputs.x.value))
self.ctx.inputs['y'] = orm.Int(abs(node.inputs.y.value))
return ProcessHandlerReport()
If the exit_codes keyword is defined, which can be either a single instance of ExitCode or a list thereof, the process handler will only be called if the exit status of the node corresponds to one of those exit codes, otherwise it will simply be skipped.
Multiple process handlers¶
Since typically a base restart work chain implementation will have more than one process handler, one might want to control the order in which they are called.
This can be done through the priority keyword:
@process_handler(priority=400, exit_codes=ArithmeticAddCalculation.exit_codes.ERROR_NEGATIVE_NUMBER)
def handle_negative_sum(self, node):
"""Handle the `ERROR_NEGATIVE_NUMBER` failure mode of the `ArithmeticAddCalculation`."""
self.ctx.inputs['x'] = orm.Int(abs(node.inputs.x.value))
self.ctx.inputs['y'] = orm.Int(abs(node.inputs.y.value))
return ProcessHandlerReport()
The process handlers with a higher priority will be called first.
In this scenario, in addition to controlling the order with which the handlers are called, you may also want to stop the process handling once you have determined the problem.
This can be achieved by setting the do_break argument of the ProcessHandler to True:
@process_handler(priority=400, exit_codes=ArithmeticAddCalculation.exit_codes.ERROR_NEGATIVE_NUMBER)
def handle_negative_sum(self, node):
"""Handle the `ERROR_NEGATIVE_NUMBER` failure mode of the `ArithmeticAddCalculation`."""
self.ctx.inputs['x'] = orm.Int(abs(node.inputs.x.value))
self.ctx.inputs['y'] = orm.Int(abs(node.inputs.y.value))
return ProcessHandlerReport(do_break=True)
Finally, sometimes one detects a problem that simply cannot or should not be corrected by the work chain.
In this case, the handler can signal that the work chain should abort by setting an ExitCode instance on the exit_code argument of the ProcessHandler:
from aiida.engine import ExitCode
@process_handler(priority=400, exit_codes=ArithmeticAddCalculation.exit_codes.ERROR_NEGATIVE_NUMBER)
def handle_negative_sum(self, node):
"""Handle the `ERROR_NEGATIVE_NUMBER` failure mode of the `ArithmeticAddCalculation`."""
return ProcessHandlerReport(exit_code=ExitCode(450, 'Inputs lead to a negative sum but I will not correct them'))
The base restart work chain will detect this exit code and abort the work chain, setting the corresponding status and message on the node as usual:
$ verdi process status 1951
ArithmeticAddBaseWorkChain<1951> Finished [450] [1:while_(should_run_process)(1:inspect_process)]
└── ArithmeticAddCalculation<1952> Finished [410]
With these basic tools, a broad range of use-cases can be addressed while preventing a lot of boilerplate code.